18363620917
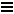
有时候在查询的时候为了避免结果重复使用distinct来去掉重复项,这个在数据少的时候还是可以的,但是数据多了,执行效率将会非常慢,有人说这不废话吗,数据多了当然慢。不是这样的,我在项目中测试过2万多条数据。慢到直接超时,程序调用时无法打开,这就非常有问题了。如下图,只放50条数据。
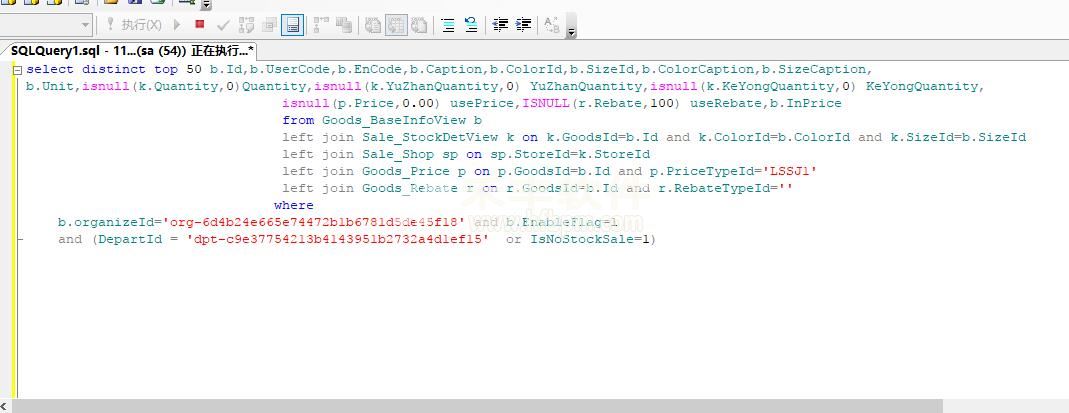
去掉dinctinct后,打开非常快,几乎是秒开。如下图:
先不说Sql语句优化的问题,单说这个dictinct的性能还是非常低的。在大数据查询的时候,过滤重复项还是要另想办法!


